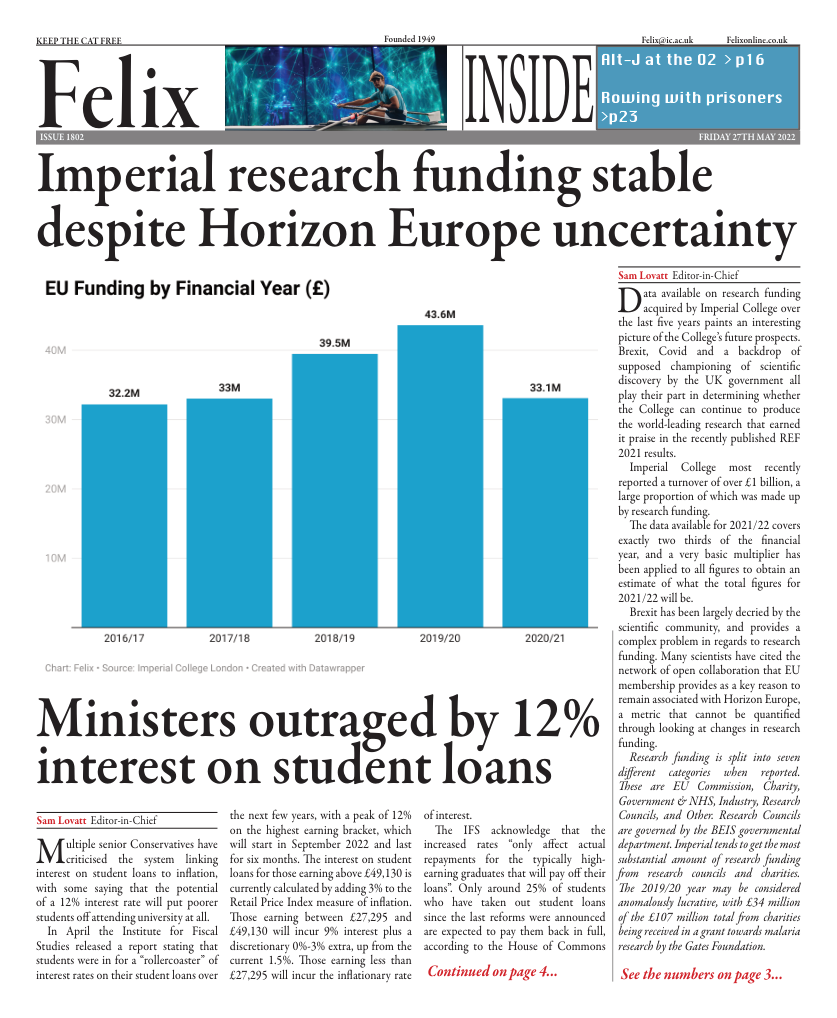
Computers will make our drugs in the future
The development of AI and large datasets will help automate the processes of drug discovery and development.

Drug discovery is a hard, time-consuming and expensive process. A single drug spends around 10 years in the lab before being released into the market. Furthermore, more than 99% of all the potential drugs end up unsuccessful. The rise of AI, as well as giant databases, seem to promise a new future in which drugs will be developed quicker, but will also be safer and more effective.
Before developing any drug, we need to find a biological site of interest that can be related to a disease. For example, GPCRs are cellular receptors that regulate cell proliferation and are involved in many cancers. Thus, creating drugs targeted at GPCRs is sensible and indeed, GPCRs are one of the main areas of research in our fight against cancer. The discovery of a potential biological site is challenging because sometimes we cannot characterise it entirely and/or delivering the drug to it would not be an easy task. This also means that we need to study many different biological sites, usually thousands of them through experiments, which takes up time and money. Using AI to run simulations of biological sites allows us to screen them much faster as we are not limited by how many experiments we can carry out.
Now that the drug target is identified, we need to actually develop our drug. Traditionally, this is done by humans through trial and error, but maybe in the future, computers could design the drug for us by analysing the structure of the biological site through simulations and dataset evaluation. Large and reliable datasets are essential for machine learning - the process by which computers ‘learn’ from data – as it allows for better performance, and so better and faster drug discovery. Precisely because the datasets must be large, these will arguably force labs and pharmaceutical companies around the world to share the data of their research with each other in order to increase the performance of computers in drug discovery. Could this make patents and IP obsolete? The traditional way of making money from pharmaceutical research would not be as effective as it is today. In that hypothetical future, the benefits of sharing your information are much greater than keeping it for yourself. There are two main types of data: sequence and imaging data. The first one is about the sequences of DNA, RNA and proteins, whereas the second is about structures of molecules/cells like proteins/mitochondria. There is another type of data that has the potential to revolutionise the way we understand genetics and drug discovery: epigenetic data, meaning the changes in gene activity caused by the environment. However, epigenetic data is very variable between individuals. Thus, the data is subject to particular interpretations and may not be easily storable.
Computers acquire information from these large datasets to integrate into their behaviour patterns to optimise their responses in a process called deep learning. The capability of deep learning is unbelievable. With it, computers can determine the structure of proteins by just reading their amino acid sequence. This is a milestone in molecular biology, as predicting how proteins fold has been impossible for humans to determine as there are too many factors to take into account.
Having said that, a world where all drugs are designed by computers is still far away. Even though there are many companies dedicated to this area of research and there are already functional prototypes, the pharmaceutical industry moves very slowly and mass-scaling a product is complicated not only due to logistics but also the necessity to guarantee high efficiency and safety.
To conclude, at present, there is a need for significant investment, in order to develop and commercialise drugs. Pharmaceutical companies and research institutions are under constant pressure to obtain more patents, which do not necessarily succeed in the goal of drugs: to improve people’s quality of life. Not only could computers dramatically accelerate the drug development process, but they might also democratise it by forcing organisations to make their data public.